
You Don’t Have to Sacrifice Machine Learning Precision for Explainability
Artificial intelligence and machine learning are rapidly on the rise. Having just attended Forrester’s Data Strategy and Insights Conference in Orlando, FL, we heard these terms frequently mentioned in many presentations.
A common perception, however, given the reality of most machine learning methods, is that you must sacrifice precision for explainability. This is because explainability requires simplification of a machine learning algorithm itself to get to the underlying feature set driving a prediction, or is opaque in the first place based on its very nature. I encounter this perception often because, by and large, it’s true.
Let’s take a decision tree for example. To be more accurate, gradient boosting (GBM), takes an ensemble of decision trees and strings them together to include the predictive power from multiple overlapping regions of a feature space in the data set represented by multiple trees.
As a result, it’s impossible to back track, with hundreds of trees, as to what features are the driver of the predicted outcome. To explain a decision tree is to use fewer of them, but that degrades accuracy.
Challenges of Explainability
In Forrester Research’s recent report, Evoke Trust with Explainable AI, November 2018, challenges with explainability are highlighted, such as why neural networks are inherently opaque.*
“In the case of neural networks, this is because they automatically extract features from data and weight those features through a process called backpropagation. Backpropagation continuously optimizes toward a specific goal, such as predictive accuracy, but the resulting logic gets obscured by the manifold interactions between neurons in the network’s hidden layers.” In short, a neural network is not explainable.
When we meet with data scientists, they are often surprised that, with our technology, based on similarity and metric learning functions, you don’t sacrifice performance for explainability.
We have overcome this challenge by using a combination of technologies that are inherently explainable, can operate at commercial speed and scale for large organizations, and can match or outperform any other machine learning method.
How do we do it? This article provides a high-level description of the underlying method and technology characteristics that enable explainability with precision. But before we get into a technology description, its useful to define what “explainability” means.
What is Explainability Anyway?
There are multiple perceptions of what machine learning explainability is depending on where you sit – everything from – “my regression models are explainable” (yes, they are but that isn’t machine learning!), to explaining the data and its weights that are an input to a machine learning algorithm.
Depending on the use case at hand and business requirements, different levels of explainability exist. In Forrester’s, Evoke Trust with Explainable AI, these different levels of explainability are defined in four categories:
- Mostly opaque, with primary responsibility on users
- Partially opaque, with auditability options
- Partially transparent, with user controls to toggle accuracy
- Fully transparent and explainable
In the report, simMachines, Founder and CTO, Dr. Mueller Molina’s approach, based on similarity, is summarized as follows:
“Some vendors position the transparency of their algorithms as a critical strategic differentiator. Arnoldo Müller-Molina, founder and CTO of simMachines, takes a hard line on the topic of transparency versus opacity, advocating an approach in which the model and the underlying data are fully transparent and explainable. Müller-Molina supports this approach not only to defray risk; he believes that if humans and machines are to work together effectively, humans must understand underlying machine logic. Inderpal Bhandari, global chief data officer of IBM, echoes a similar sentiment with regard to the future of AI technology, believing that ultimately the output of AI will need to be fully transparent.”
In general, explainable AI (XAI) continues to be increasingly important for many reasons, and the methods you choose limit or expand explainability.
In the case of similarity, it is at an individual local prediction level, vs. a global explanation of the model itself. That, in and of itself, is a significant difference between methods.
In credit modeling, regulators are used to being given the algorithm with the weights exposed by feature that describe what the algorithm is doing. That is one level of explainability, but it doesn’t directly answer the question an individual consumer may have which is, “why was I denied credit?” With regression models, basic reason codes are exposed, but with machine learning, at an individual local prediction level, this would be very difficult.
Would a consumer ever ask, “please describe the algorithm and its characteristics that was used in making this decision?” I don’t think so.
For marketing, risk and fraud applications where consumer privacy, ethical uses of data, a consumer’s right to an explanation under GDPR regulations, other regulatory requirements and internal adoption and trust of what the algorithms are deciding, there are many reasons to ensure the right level of explainability is built in.
Achieving Precision and Explainability is Possible with Similarity
So now let’s explore how similarity solves this problem.
Similarity Machine Learning and Explainability
First, similarity can be used to implement KNN (K Nearest Neighbor), which is a method that retrieves similar objects to the object of a prediction and uses those similar objects as the underlying basis for making a prediction.
Those similar objects also provide the feature set that enables the prediction to be explained. Their attributes and proximity, or distance, to the object being predicted also tell you “Why” the prediction is being made.
KNN is one of the most accurate machine learning methods. However, the historical problem with KNN is its ability to scale. That’s why data scientists have chosen mostly other methods for commercial grade applications.
simMachines founder, Dr. Arnoldo Mueller, conducted breakthrough research to scale similarity. After spending many years at the Kiyoshi Institute in Japan studying similarity as a method for cracking the “black box” problem inherent with other methods, Dr. Mueller invented methods to quickly search for nearest neighbor objects regardless of the number of objects (rows) or features (columns) in a data set. This enables KNN, when implemented with similarity, to scale.
Overcoming the curse of dimensionality issue that creates enormous computational challenges when using Euclidian distance calculations wasn’t a simple task. Metric Learning is a perfect solution to overcome this curse, as we shall see later on.
Part of the IP of simMachines’ method is in its ability to enable similarity to run at massive scale, and to reveal “the Why” behind every prediction. However, Arnoldo did one other thing…enable not just the exposure of the key features associated with a predicted outcome, but also the weighting of those features based on their level of importance to the prediction. This is called dynamic feature weighting which occurs in real-time when a prediction is made.
Dynamic Feature Weighting Equals Insights
Dynamic Feature Weighting prioritizes every feature associated with an individual prediction in order of importance. This is unique and powerful as it rank-orders the primary drivers of the predicted outcome based on their weight or frequency of appearance, as well as the proximity of the objects to the predicted object from which they appear.
CHURN EXAMPLE
In the below example, a traditional ML open source algorithm after training will ingest a query object and make a prediction:
Question: Will this customer cancel their mobile phone plan?
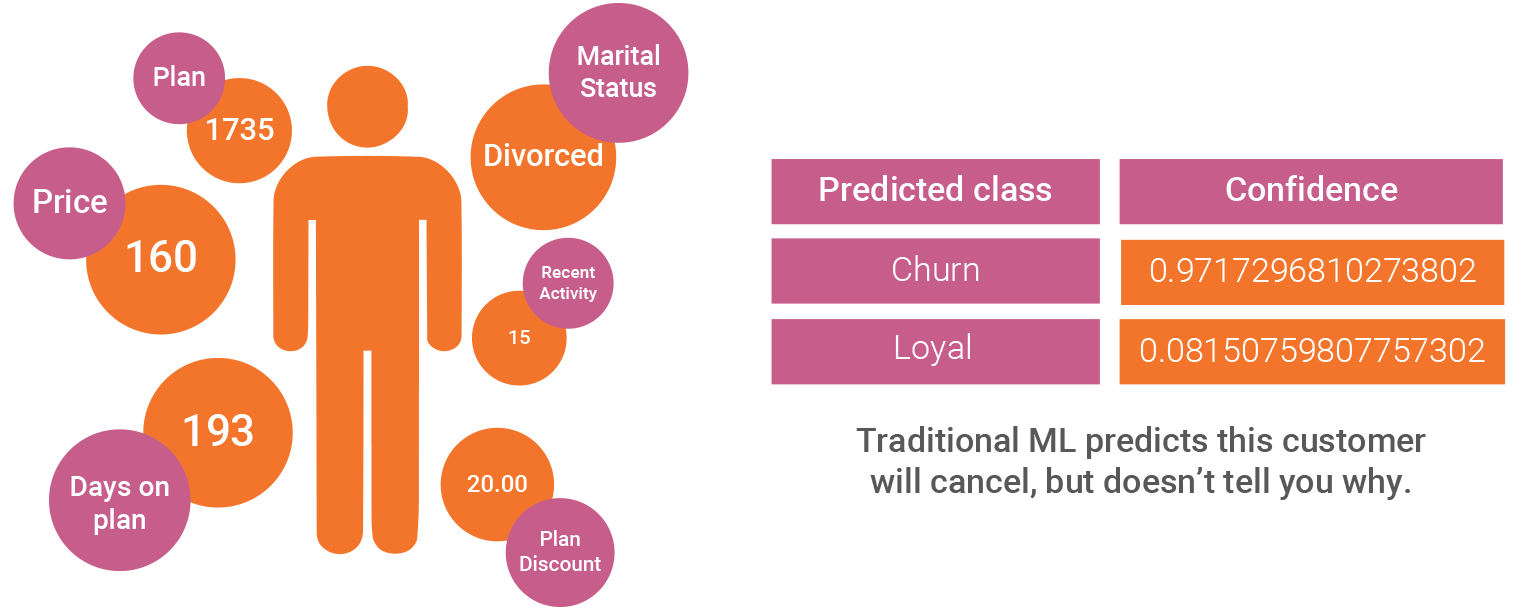
Without knowing why someone is going to churn, what do you do? What preventative action should be taken? Do we want to keep this customer in the first place? Is this customer easy or difficult to retain given their reasons for potentially leaving? These questions can’t be answered except based on internal subjective opinions overall about what drives customer behavior.
However, with similarity, we can return the same prediction, and expose in order of importance, the every data feature associated with making this prediction.
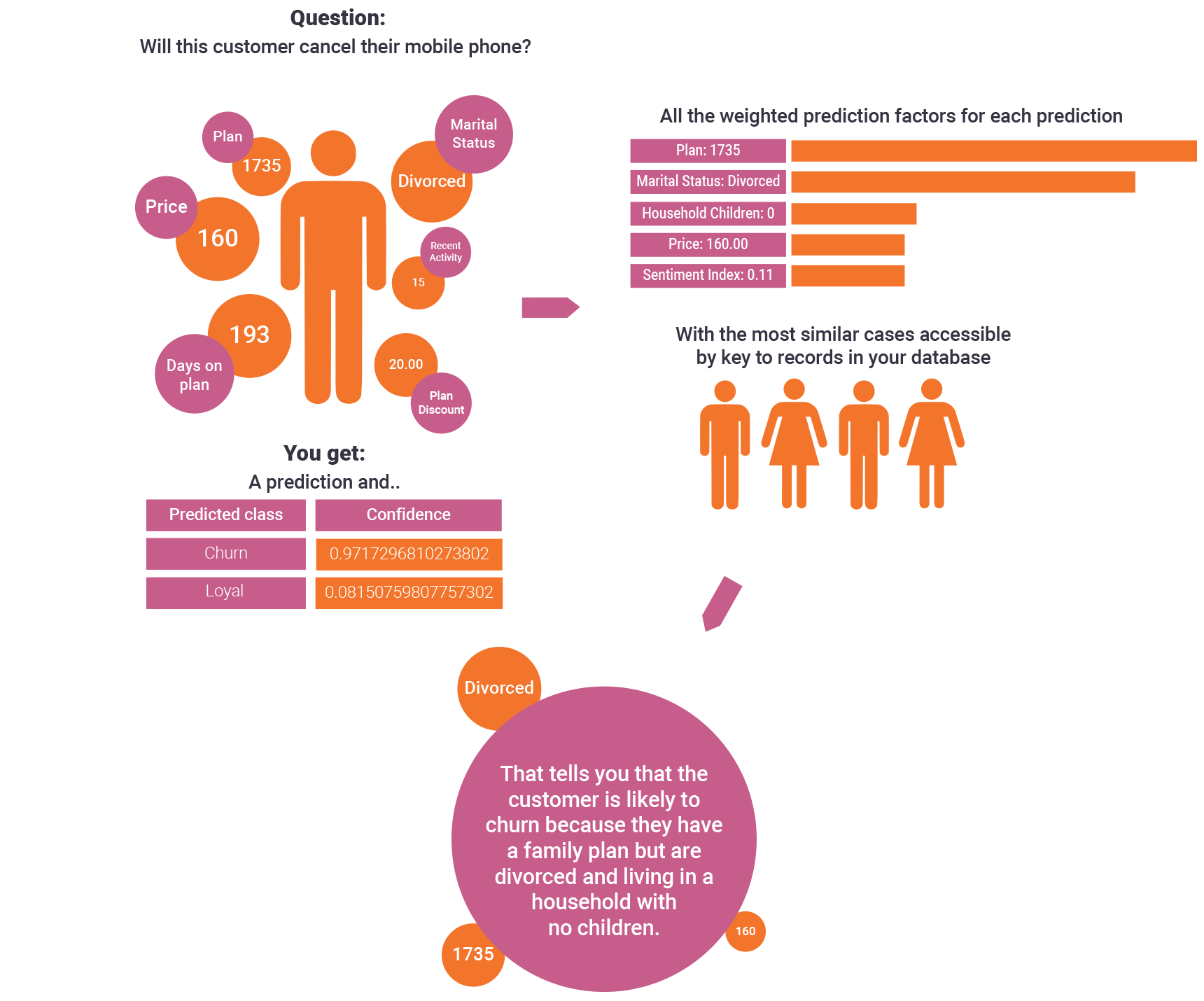
In this case, similarity reveals that the churn prediction customer is on a family plan, recently divorced without children in the household and will churn, as other divorced no children customers previously did, because the price of the plan is too high.
Now you can offer this “likely to churn” customer an individual phone plan proactively. In fact, you can group together all of the predictions that have these weighted features in common and treat them with the same preventative offer. This is called Dynamic Predictive Segmentation. This is the value of dynamic feature weighting.
Metric Learning Equals Precision
Third, the other ML, “metric learning” is how state of the art precision is achieved.
A library of distance functions is available and the machine selects the best distance function automatically, as part of the model creation and self-validation process. Euclidean distance is commonly used but there are many other distance functions that can create a more accurate comparison of similar objects to the predicted objects.
In essence, the software is able to see more similar objects as closer together and less similar objects as farther apart than standard Euclidean distance functions. This yields much greater precision!
Performance Comparison
Hundreds of tests against other models proves that this method holds up as equally or more precise while providing explainability at a local individual prediction level as described above. Performance is easily tested and proven through an evaluation where the same data set and hold outs are run through multiple different approaches.
Real performance data benchmarks from evaluations are summarized below:

By comparison, similarity often outperforms, by a little or a lot, other statistical and machine learning methods in degree of precision, while providing explainability. Furthermore, the technology is also scaleable for speed and can be optimized for performance needs with the appropriate hardware configurations.
Commercial Benefits of Explainable AI
The business impact of explainability is another aspect to consider. The impact of speed to insight through faster analysis and deeper understanding of the drivers of changing consumer behavior is one key area.
Greater relevancy in marketing is another. The holy grail in marketing is high relevancy during each and every customer interaction. In order accomplish this, an enormous amount of transaction data has to be ingested, processed, and analyzed – with predicted customer needs and behavior updated and ready to feed marketing programs and real-time interactions.
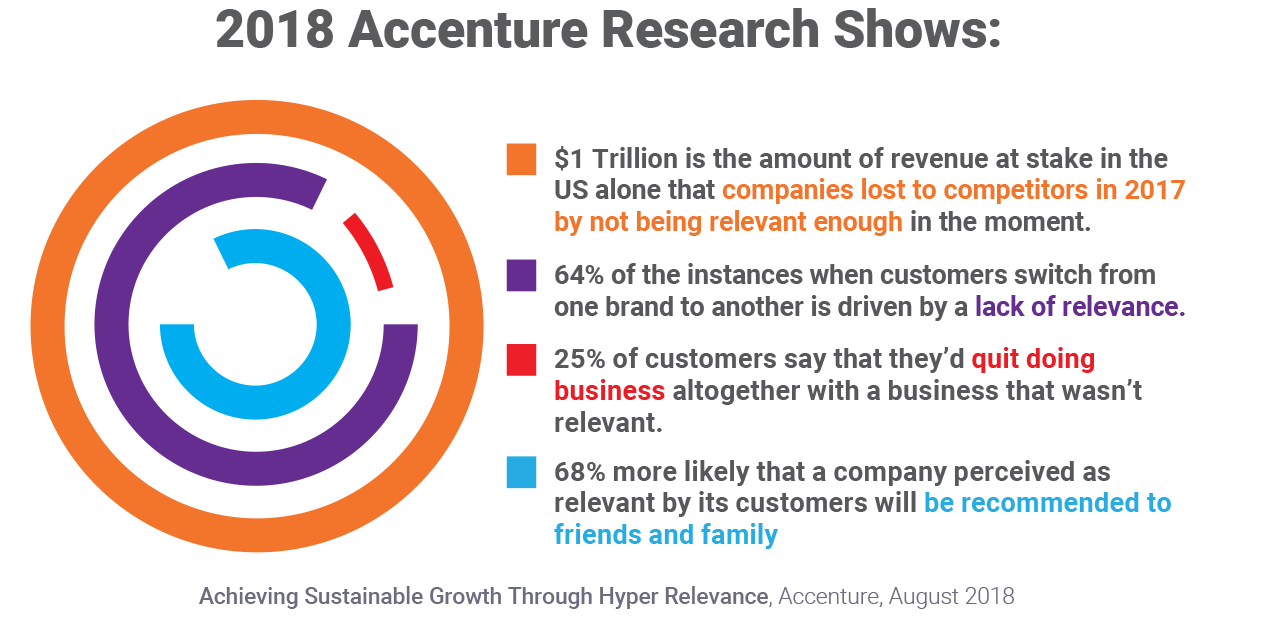
Only machine learning can keep up with the scale and pace – but without explainability, how do you know what offers and messages to deliver? In the age of the customer, relevancy is competitive advantage as called out in Accenture Research, Achieving Sustainable Growth Through Hyper Relevance, August, 2018.
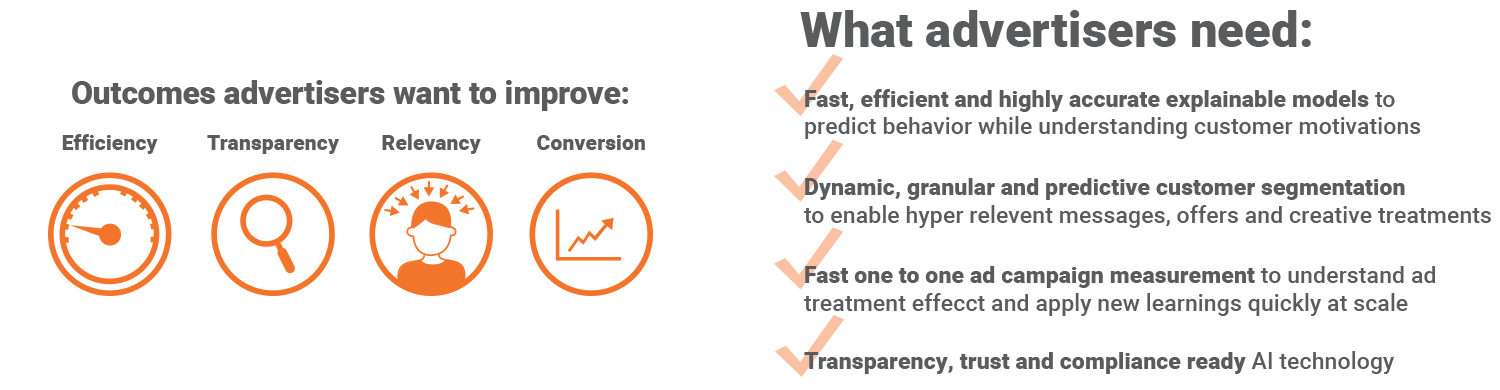
COMMERCIAL BENEFITS FOR EXPLAINABLE AI LARGELY FALL INTO THREE CATEGORIES:
• Efficiency – XAI enables functions that require an explanation as part of their process flow to run much faster in terms of time and hours spent vs. alternative methods. Examples include:
- Reduce marketing model development and customer segmentation time by 80%
- Reduce review rates for fraud models by 30%
- Reduce campaign cycle times by 50%
• Insight – XAI reveals insights about why something has or will happen. Examples include:
- Reveal new customer segments 80% faster
- Spot new emerging fraud patterns and trends that couldn’t be seen before, preventing millions of dollars in losses
- See and understand why a computer or engine part is predicted to break or how an intrusion defeated system security protocols
• Relevancy – XAI provides the factors for predicted customer behavior in weighted factor order to enable offers, message and creative to be adjusted to the real drivers of predicted behavior. Examples include:
- Reduce churn by 30% by aligning preventative messaging and offers to reasons why
- Personalize email campaigns at a one to one level to increase open rates by 50%-100%
- Enable real-time recommendations that more personalized to drive 10% to 20% increase in online conversion
Not all use cases require explainability. But when it comes to your brand and evoking trust through transparency, ethical and legal compliance capabilities, increased insights and understanding – why wouldn’t you use explainability when it can match or outperform black box methods?
*Access requires subscription or purchase.


