
Similarity Based Machine Learning Provides AI Transparency and Trust
Similarity is a machine learning method that uses a nearest neighbor approach to identify the similarity of two or more objects to each other based on algorithmic distance functions. In order for similarity to operate at the speed and scale of machine learning standards, two critical capabilities are required – high-speed indexing and metric and non-metric distance functions. As a method, similarity is different than:
- Neural Networks which create vector nodes to predict an outcome
- Decision Trees which create multiple trees that branch down to predictions
- Deep Learning which uncovers hidden layers underneath artificial neural networks
- Natural Language Processing (NLP) which mimics human language in conversation
All of these methods fall under the machine learning umbrella of Artificial Intelligence. Similarity, as a method, along with neural networks and decision trees, all predict future outcomes. Deep learning and NLP do not. However, only one method can provide an explanation behind a prediction, at a local prediction level. In other words, the factors driving one prediction are different than the next prediction as revealed by the algorithm. That one method is Similarity.
Only one method can provide an explanation behind a prediction, at a local prediction level. In other words, the factors driving one prediction are different than the next prediction as revealed by the algorithm. That one method is Similarity.
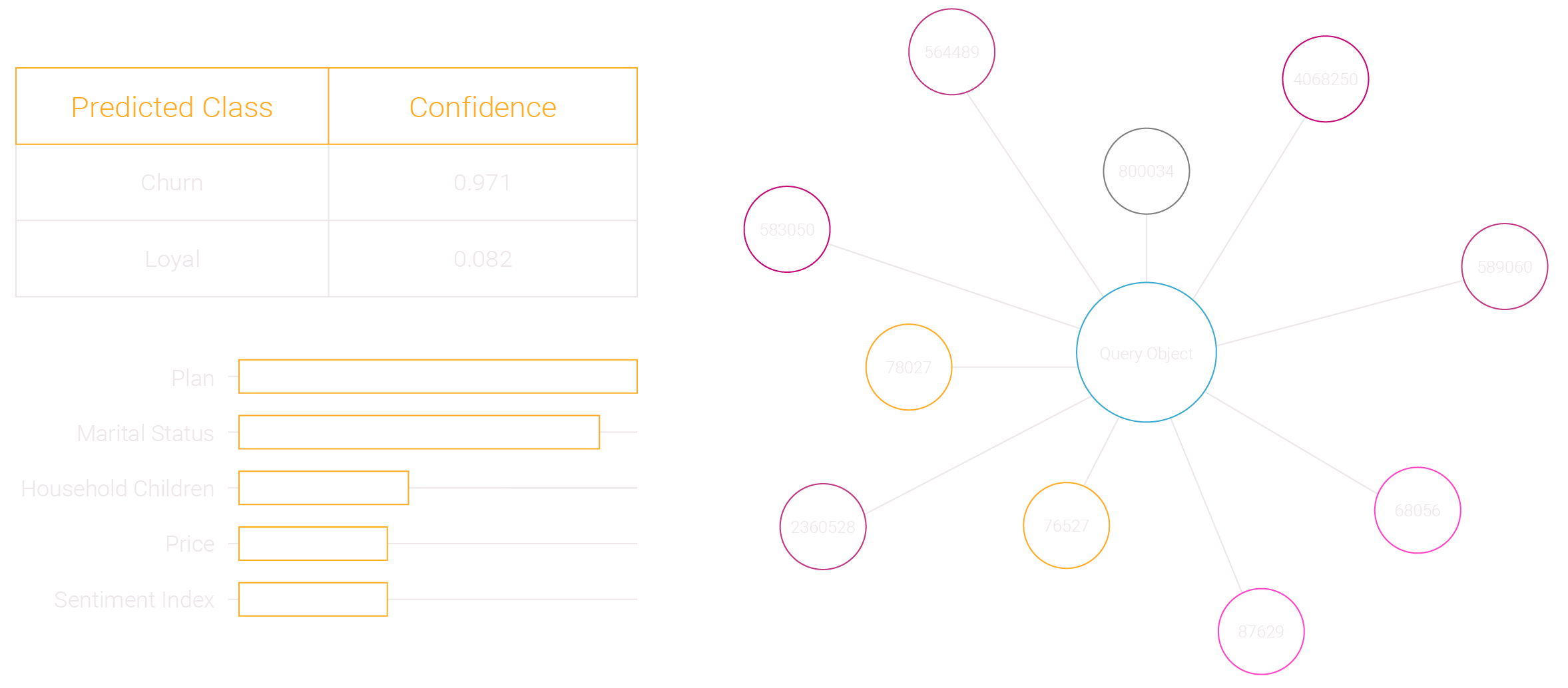
Once you have these factors, by prediction, you can execute real time interactions with tremendous insight into the context of each one, as the prediction factors reveal all of the key characteristics associated with the prediction by data element or factor.
Why one customer is calling to cancel service vs. another, or make a purchase vs. another, can be driven by completely different factors. Therefore, it is now possible to treat each individual interaction, driven by a similarity based machine learning prediction differently, by leveraging the weighted factors to drive the selection of one offer and treatment vs. another.
Similarity creates uniquely valuable outputs and handles certain applications that other alternative machine learning methods can’t. Similarity reveals what’s behind the mind of the machine to humans so humans can decide what actions to take. It provides powerful insights and capabilities that, through transparency, engender trust and understanding.


