

Transparent Machine Learning Predictions
Other machine learning methods provide a prediction – simMachines provides much more. With every machine learning prediction, our technology reveals the justification for the prediction – or “the Why” – providing insights into what factors are driving the prediction, listed in weighted factor sequence. The nearest neighbors for that prediction are also provided by distance, with keys that tie back to each nearest neighbor object in your database.
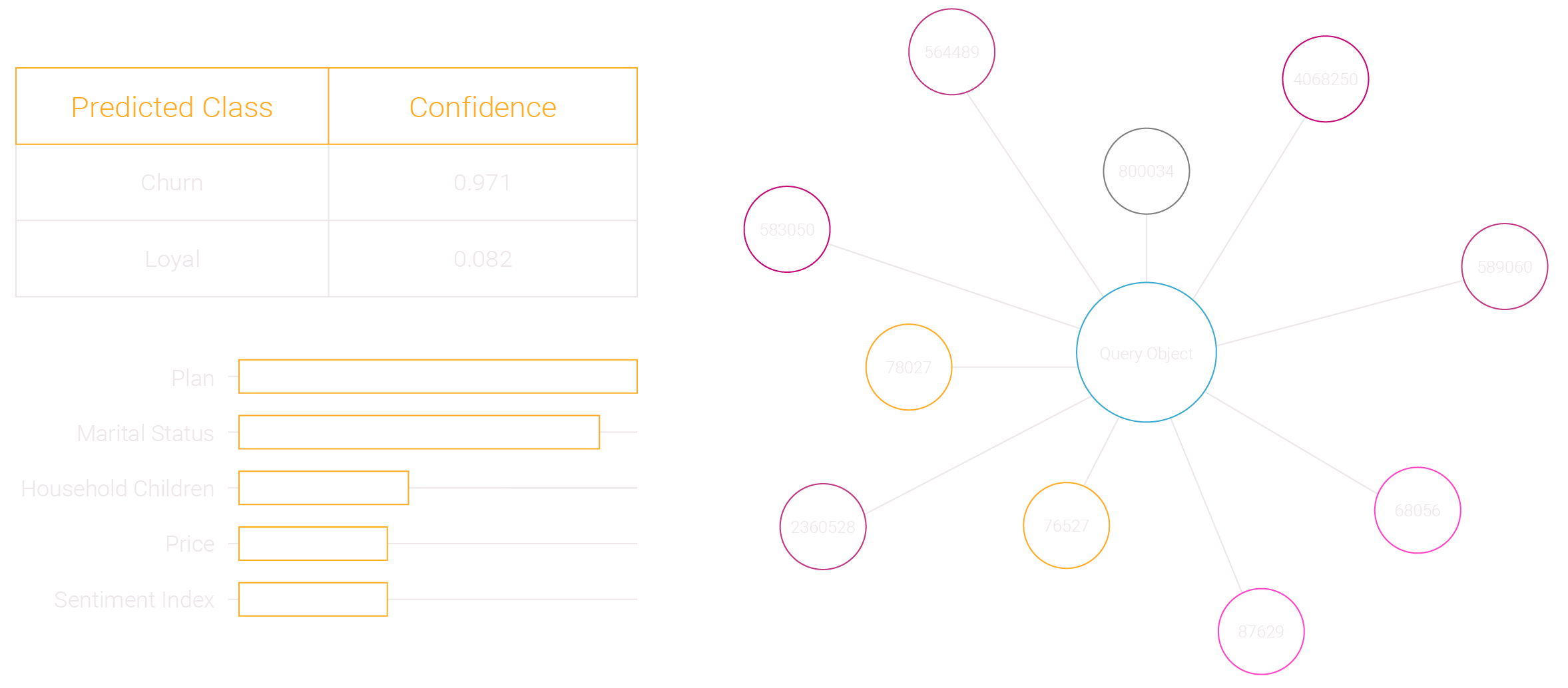
simMachines provides full transparency behind every prediction it makes. This enables business owners to understand what the machine based its predictions on at a local prediction level.
• I now know the root cause of this prediction.
• I can see the individual factors driving the prediction and their importance.
• Now I can take an informed action with confidence.
Traditional Machine Learning’s Limitations: Every machine learning algorithm will generate a prediction like the one in the example above. Machine learning’s “black box” problem is that a prediction is made, but the business user doesn’t know why.
• What is the root cause of this prediction?
• What are the factors associated with this prediction?
• Can I use this prediction to make an informed action?
Explainable AI (XAI) Revolutionizes Marketing Segmentation


“Having transparency into why predictions are made is pretty high on the list. That goes back to believability: you need to have transparency to see how you got there. It can’t be a black box, that’s when you lose everybody.”
– Director of Shopper Marketing Initiatives, CPG company
Capture The Customer Moment With Dynamic Predictive Segmentation, a January 2018 commissioned study conducted by Forrester Consulting on behalf of simMachines
What Makes Us Different: Similarity-Based Machine Learning
simMachines uses a proprietary similarity-based machine learning (nearest neighbor) method vs. decision trees or neural networks, to provide the Why behind every machine learning prediction. No other machine learning method can provide “the Why” at a local level.

The similarity of an object to another (nearest neighbor) is commonly employed in customer segmentation, using statistical modeling techniques, as the Why factors behind the similarity of two objects is critical for downstream marketing actions to occur. When applied in machine learning, the same value is provided. However, historically, similarity-based approached could not scale because of the Curse of Dimensionality. simMachines is the first and only technology to solve this problem.
Other machine learning methods do not compare

Neural Networks
Inherent in this approach are multiple neurons that input objects to create an output. However, there is no way to know which input factor resulted in the output, so only the prediction can be provided, but not the Why factors behind the predictions.

Decision Trees
Inherent in this approach is the requirement to build thousands of trees and then use gradient boosting methods to optimize across them. Single tree predictions aren’t very accurate and gradient boosting is time consuming, hard to maintain, and cannot carry forward the factors behind their predictions, due to complexity.
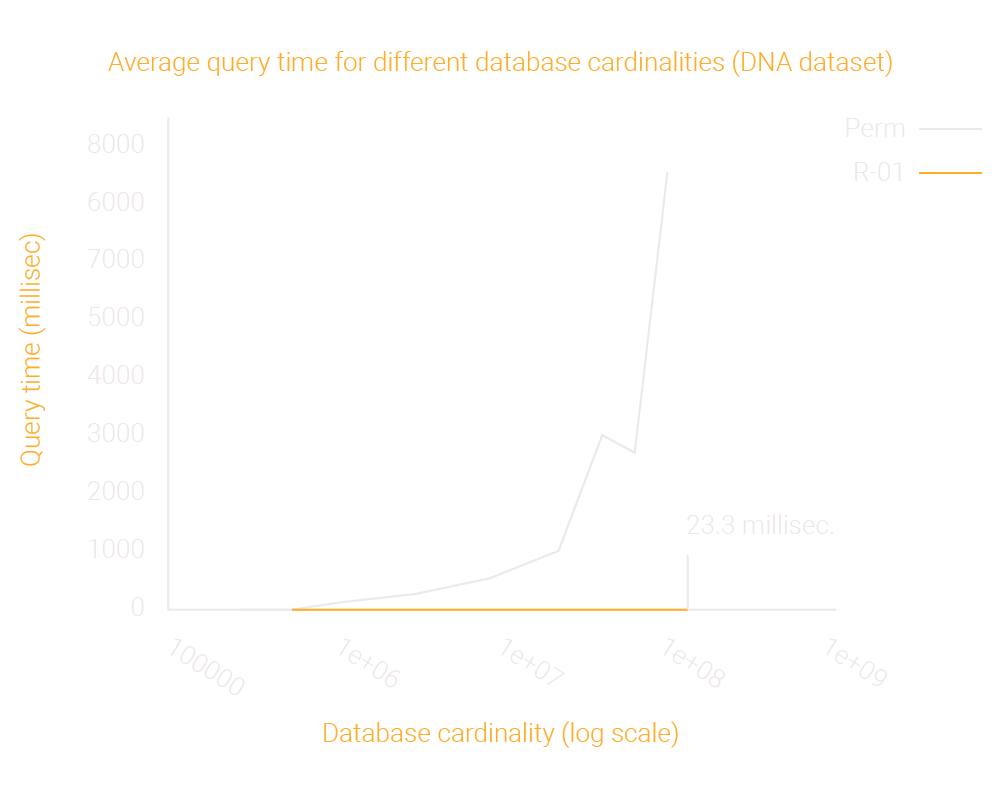
Similarity-Based Machine Learning at Speed and Scale
simMachines leverages its state-of-the-art similarity-based machine learning engine to outperform other approaches in terms of speed and precision, while providing the justification behind each prediction. The advances we have made allow similarity to be used in business applications previously believed to be unfeasible, paving the way for a variety of unique use cases.
Our technology can use any distance function – metric or non-metric. This allows us to handle data in its native form, significantly improving accuracy and gives us the ability to easily handle both structured or unstructured data.
We use a dynamic dimension reduction technique to identify the variables required to make an accurate prediction. As a result, our engine is able to provide the input variables that most strongly influenced the prediction, providing transparency to the machine learning process.
Comparison: Machine Learning Algorithm Types
The following is a comparison of the different types of machine generated algorithms. simMachines offers the broadest set of features and capabilities in comparison to other algorithm types.
